Stable Video Diffusion
近年來,隨著人工智慧技術的快速發展,生成式AI在影像與影音領域的應用與創新愈加廣泛。基於影像模型Stable Diffusion的基礎影片生成模型Stable Video Diffusion。其具備高度適應性,可廣泛應用於多種影像與影片生成任務。例如,透過多視角資料集進行微調,模型能夠從單張影像合成多視角影片。該模型經過訓練,在給定相同大小的上下文幀的情況下,以 576x1024 的解析度生成 25 幀,並微調了廣泛使用的 f8-decoder 以實現時間一致性,最後模型還提供標準的逐幀解碼器。效果如下:
寫實版本的效果


卡通版本的效果


本計劃將演示這一系列技術,並展示出與Stable Diffusion系列模型的整合多樣化應用,為使用者介紹生成式AI在影像領域中,如廣告、教育、娛樂等多個領域的實際應用價值。
- 電商平台:透過圖片生成產品展示影片,讓顧客更直觀地了解商品特性,例如模擬使用場景或展示產品細節。
- 教育與培訓:以圖片生成教學影片或模擬實驗過程,提供更具互動性與視覺吸引力的學習體驗。
- 遊戲產業:快速生成遊戲角色動態或場景過渡動畫,加速遊戲開發過程並提升視覺效果。
- 建築與室內設計:將設計草圖轉換為動態展示,幫助客戶更直觀地理解空間規劃與設計理念。
圖片生成影像技術不僅擴大了內容創作者的可能性,也有助於降低專業知識的門檻,讓更多人能夠參與影片創作。同時,這項技術還能幫助企業快速響應市場需求,創造高效且個性化的視覺內容,提升競爭力。
Stable Video Diffusion (SVD) 是一種潛變視訊擴散模型(Latent Video Diffusion Model, LDM),專門用於影像生成影片(Image-to-Video),建立於Stable Diffusion 2.1 基礎上,並透過Diffusion Model來產生影片。主要架構包括:
基礎模型
- 由Stable Diffusion 2.1 延伸而來
- 採用去雜訊(denoising)的方式,從隨機噪聲逐步生成影片
- 加入時間序列層(Temporal Layers),確保影格之間的運動一致性
訓練流程
- 階段 I:影片預訓練(Video Pretraining)
- 使用超過6 億筆影片資料
- 透過Optical Flow Analysis篩選高動態影像
- 階段 II:高品質影片微調(High-Quality Video Finetuning)
- 使用25 萬筆精選影片樣本進行微調,以提升最終輸出品質
時間序列層(Temporal Layers)
- 插入於Spatial Convolution與Attention Layers之後
- 用於增強影片的時間一致性
LoRA 模組(Low-Rank Adaptation Modules)
- 訓練LoRA,可用於特定的攝影機運動控制
- 支援平移、縮放、靜態等視角變化
多視角與 3D 先驗(Multi-View & 3D Prior)
- 可基於單張圖片生成多視角影片
- 效果優於Zero123XL 等專門用於新視角合成的模型
資料處理流程
- 文本/圖片嵌入(Embeddings)
- 透過 CLIP 或 Stable Diffusion 2.1 處理文本與圖像條件(Conditioning)
- 影片生成
- 透過 潛變空間(Latent Space) 進行低解析度影像合成
- 透過時間序列層(Temporal Layers) 增強影片運動連貫性
- 最後將影片解碼回像素空間(Pixel Space)
- 輸出影片
- 解析度可達 576×1024 或更高
- 人工評估視覺品質與文本匹配度
- 可透過 LoRA 模組 控制特定鏡頭運動
- 影片以 MP4 / WebM 格式輸出
參考資料
試玩 Stable Video Diffusion (SVD)
- Step1:點選喜歡的範例圖片,按下 Play 就會生成出對應的影片。
- Step2:拉動左側參數調整的動作變化量與噪點量,會生成根據參數調整的影片。
- Step3:勾選參數調整的卡通風格,會生成出透過 LoRA 技術微調過宮崎駿風格的圖片,並同時生成出相對應的影片。
- Step4:在未來我們將會為各位解鎖更可以調整的參數,敬請期待!
按下「試玩SVD」按鈕,開始試玩:

聊天機器人
大型語言模型(Large Language Model,簡稱 LLM)是當代人工智慧技術的一大里程碑。透過海量數據訓練,這些模型能夠理解並生成自然語言,從而應用於各類語言處理任務。我們的系統正是建立在這項技術之上,運用最先進的 LLM 來驅動聊天機器人的運作,以提供自然流暢的對話體驗。
為了提升系統的準確性與靈活性,我們採用了多代理人(multi-agent)協作架構。這表示,系統並非僅依賴單一 LLM,而是透過多個模型分工合作,使回答更精確、更具深度與廣度。在處理複雜問題時,各個模型能發揮各自的專長,共同提供最佳解決方案。為了實現這一點,我們選用了當前最受歡迎的開發工具——langchain 與 langgraph。這兩套工具不僅受到技術社群的高度推崇,也能夠有效整合多代理人的運作流程,使系統開發與維護更加高效與便捷。
此外,為了確保回應內容的時效性與準確度,我們引入了 RAG(Retrieval Augmented Generation,檢索增強生成) 技術。簡而言之,RAG 結合了資訊檢索與語言生成的能力,使系統能夠即時從外部資料庫或內部資源擷取最新資訊,並將其融入回答中。這項技術不僅提升了系統對時事與特定領域資訊的掌握度,也使回答內容更加豐富且可靠。
透過大型語言模型以及多種相關技術的整合,打造出既能應對日常對話需求,又能處理專業性問題的智能聊天機器人。希望對此領域有興趣的使用者,透過這篇技術分享能提供一個清晰的概覽,幫助理解大型語言模型、多代理人協作以及 RAG 技術在實際應用中的價值與優勢。
在現代企業中,基於大型語言模型(LLM)的聊天機器人正迅速成為數位轉型的重要驅動力。這些系統不僅具備先進的自然語言處理能力,更能夠結合上下文分析與多任務學習,為企業提供全方位的智能服務。首先,在客戶服務領域,LLM 聊天機器人可自動化處理常見詢問,大幅降低客服人員負擔,同時通過深度學習持續優化回覆品質與用戶體驗。其次,商業智能與數據分析亦因此獲得提升,透過與內部知識庫及實時資料的整合,系統能夠快速解答專業問題,協助決策者進行準確判斷。
此外,LLM 技術在行銷推廣與銷售轉化中發揮關鍵作用,透過個性化對話與動態互動,精準捕捉消費者需求,實現產品推薦與精細化管理。企業可藉此減少營運成本,提升服務效率與品牌競爭力。總之,隨著技術不斷演進,我們的系統在智慧客服、內部資訊管理以及市場行銷等多個應用場景中展現出強大的商業潛力,成為推動企業數位化轉型的核心利器。
我們的系統專為中山大學的選課查詢與相關規定解答而設計,整體架構可分為「資料建置」與「問答流程」兩大部分,並採用 langgraph 架構 multi-agent 協作模型,以提升回應的精準度與靈活性。
資料建置
首先在資料庫建置階段,我們分別建立了課程資料庫與規定資料庫。
- 課程資料庫:透過自動化爬蟲從中山大學選課系統中獲取本學期課程的最新資訊,並直接存入 MongoDB,以便於後續查詢與統整。
- 規定資料庫:從中山大學官網獲取所有選課相關文件,利用 chunking 技術將文件內容拆分成多個文本片段,並透過 embedding 技術轉換成向量,最終存入 chroma vectorDB,以支援後續透過語義相似度(cosine similarity)的查詢。
問答流程

在執行步驟上,我們的系統依據使用者的輸入語句採取不同的處理流程,其主要流程如下:
- 使用者輸入語句後,LLM 進行 intent classification,將語句歸類為「選課查詢」、「規定查詢」或「out_of_scope」。
- 依據分類結果,系統決定對應的工作流。
- 若判定為 選課查詢,系統使用 LLM 的 NER(命名實體識別)技術抽取關鍵字,如老師、系所、年級、必選修、星期、時間及課程相關關鍵字,並組合 MongoDB 查詢語句,返回符合條件的課程資料。
- 若為 規定查詢,系統採用 RAG 技術,透過語義相似度比對從 vectorDB 中檢索出與使用者問句最相關的文本片段,再由 LLM 進行整合,生成最終回答。
- 若語句被歸類為 out_of_scope,系統則返回預設的提示回應,告知使用者該問題不屬於系統處理範疇。
系統優勢
透過上述架構設計,我們的系統能夠在多層次資料來源中精準匹配使用者查詢需求,並透過 multi-agent 協作機制提供高效且專業的問答服務。這種設計不僅提升了系統的靈活性與擴展性,也為處理複雜查詢情境提供了穩定可靠的技術支援。
在我們的系統中,有三個關鍵部分對系統的整體表現影響甚鉅,分別是 使用者意圖判定、關鍵字擷取 (NER) 以及 檔案檢索增強 (RAG)。以下將分別介紹這三個部分的目前表現:
1. 使用者意圖判定
此部分的主要目標是辨識使用者的意圖,以便系統能夠選擇適當的後續處理流程。我們採用 GPT-4o-mini 作為模型,並透過 Prompt Engineering 設計明確的意圖類別,包括:
- 選課查詢 (ask_course)
- 選課規則查詢 (regulation)
- 系統範疇外對話 (out_of_scope)
以下為目前系統在意圖判定方面的表現:

2. 使用者句子中的關鍵字擷取 (NER)
在此部分,我們的目標是從使用者的查詢中擷取關鍵字,作為後續資料庫查詢的依據。我們同樣採用 GPT-4o-mini,並透過 Prompt Engineering 明確定義任務內容及系統支援的關鍵字類別,例如:
- 系所名稱
- 授課老師
- 課程關鍵詞
- 星期
- 時間
- 年級
- 必選修
評估方式則參考 Named Entity Evaluation 方法,以下為評估結果:

3. RAG (Retrieval-Augmented Generation)
RAG 主要負責根據使用者的問題,檢索相關的課程規定文章,並根據檢索內容生成準確的回答。我們採用 LLM as Evaluator 機制,讓 LLM 充當評估者,使用 RAGAS 套件進行系統表現評估,評估指標包括:

檢索準確度:
- Context Precision(檢索文章的精確度)
- Context Recall(檢索文章的完整性)
回答品質:
- Answer Relevancy(回答的相關性)
- Faithfulness(回答的忠實度)
- Answer Correctness(回答的正確性)
以下為 RAG 系統的評估結果:

功能:
- 選課查詢
- 選課規定查詢
範例:
- 「幫我找企管系星期三的課」(選課查詢)
- 「資管系康益晃教授關於巨量資料的課程」(選課查詢)
- 「中山大學中如何請病假?」(選課規定查詢)
- 「初選一的時間」(選課規定查詢)
可以的查詢條件有:
- 系所 (資管系、海科博等)
- 老師 (三益老師、陳嘉平教授等)
- 課程關鍵字 (人工智慧、向度一等)
- 星期 (如:周一、星期五等)
- 時間 (如:早上、下午、傍晚等)
- 年級 (如:一年級等)
- 必選修 (如:必修、選修等)

語者自動分段標記系統
近年來,隨著人工智慧的蓬勃發展,人們開始嘗試利用人工智慧解決許多問題。語者自動分段標記(Diarization)技術也是其中之一,語者自動分段標記系統主要負責自動標記出一段音檔中不同人講話的時間點,辨識出在什麼時間點有不同人說話的活動情況。目前,語者自動分段標記系統目前被廣泛的應用在會議記錄和自動字幕生成等領域,與自動語音辨識系統(Automatic Speech Recognition , ASR)相結合,能夠辨識出不同人在甚麼時間點說了甚麼話。
本系統主要基於端到端架構實做,端到端模型將語者自動分段標記任務定義成多標籤分類(Multi-label Classification)問題。只需要將待辨識的音檔輸入模型,模型便會將音檔中不同時間點分類給不同的語者。
本系統主要基於端到端架構實做,端到端模型將語者自動分段標記任務定義成多標籤分類(Multi-label Classification)問題。只需要將待辨識的音檔輸入模型,模型便會將音檔中不同時間點分類給不同的語者。
本系統主要改進傳統端到端架構中的複雜度問題。由於傳統端到端語者自動分段標記系統採用轉換器(Transformer) 架構。導致模型無法一次行辨識較長的音訊檔案。本系統主要基於大型語言模型(Large Language Model)中之保留神經網路(Retention Network)改進。使我們的語者分段辨識系統可以一次性辨識長音檔。且在複雜度下降的同時,模型的準確度相比變換器架構依然有所提升。
架構與參考資料:
本系統主要基於端到端語者以編解碼吸收器架構增強之自動分段標記系統 (End-To-End Neural Diarization - Encdoer Decoder Attractor, EEND-EDA)實做,以下將詳細介紹系統之架構。
EEND-EDA 架構在 2019 年由 Hitachi 公司所提出,目的在改善端到端系統無法處理未知語者之情況。EEND-EDA 架構主要由編碼器(Encoder)以及編解碼吸收器(EDA)架構所組成。編碼器負責捕捉輸入音訊之特徵,並將特徵編碼成特定長度之向量。在本系統中,我們將編碼器更換成低複雜度之多維度保留神經網路,以改善長音檔辨識問題。保留網路之編碼器架構如下圖(一)所示。

而在負責預測語者數量之編解碼吸收器架構(EDA)主要由長短期遞迴神經網路(Long Short Term Memory, LSTM)所構成。透過 LSTM 架構之編解碼器,模型可以動態決定每段音檔當中有多少個吸收器(Attrzctor)。每個吸收器即待表一個語者。最後將預測之吸收器與編碼器輸出相乘,即可得到語者分段標記系統之輸出。整體 EDA 架構如下圖(二)所示。

評估結果與展示:
本語者自動分段標記系統主要由三個資料集所構成,前兩個是由自動語音辨識系統中之 Librispeech 資料集混合而成。分別為 Libri2mix 以及 Libri3mix,分別代表混合成兩個語者以及三個語者的版本。本系統主要會使用 Libri2mix 資料集做主要訓練,並使用 Libri3mix 資料集做語者微調。最後我們會使用中文資料集 ALi-Meeting 架構去對系統做語言上面的微調。
在本系統中,訓練的資料會固定在 5~10 秒左右之音檔,並且控制語者數量以訓練 EDA 架構。資料集總時數如表(一)所示。
最後我們會使用語者分段錯誤率(Diarization Error Rate, DER)指標做評估,並且測試在 GTX-1080 Ti 顯示卡上本系統可辨識的最長長度。我們將結果整理在表(二)。

試玩程式說明::
此 Web 程式分為兩個部份,第一個部份可以直接使用設備麥克風進行錄音與辨識。第二部份可以直接上傳音檔進行辨識。注意音檔格式必須為 wav 格式,並且轉為單聲道以及 8000 採樣率。
操作流程::
- 欲使用錄音辨識,請先按下錄音按鈕,待錄音完成按下停止。
- 欲回播錄音請按下播放,即可聆聽剛剛錄音的音檔。
- 欲辨識此段錄音音檔,請按下提交,辨識結果即會顯示在下方。
- 4. 欲使用檔案辨識,請按下選擇文件,選取需要辨識的音檔後按下上傳檔案即可。

臉部辨識
臉部辨識是一個日益普及的技術,它可以識別圖像或視頻中的人臉,並在各種應用中派上用場。例如,你可能已經在社交媒體上使用過臉部辨識功能,來標記照片中的朋友,或者在手機上使用臉部辨識功能來解鎖設備。此外,臉部辨識技術在行人偵測、工業影像處理等領域也有廣泛應用,例如,在製造業中,臉部辨識技術可以用來識別工人,並根據他們的身份進行安全訪問控制。
目前,主流的臉部辨識開源套件包括Yolov3和MobileNetV2,兩者均基於深度學習技術。Yolov3以其精準的物體辨識能力而脫穎而出,特別擅長小物體檢測,並提供了物體在圖像中的精確位置、所屬類別以及模型對預測的確信程度。相對而言,MobileNetV2專為移動設備優化,其輕量化結構使其適用於資源有限的手機或嵌入式裝置,特別適合應用在相機和智能手機等移動設備上的即時影像處理。
如果您對臉部辨識領域抱有濃厚興趣,我們期望這些介紹的工具和套件將對您打造個人臉部辨識系統提供實質協助!
在現今社會中,隨著科技的進步,各部門、機構對於使用者身分驗證的需求也大幅上升,因此也使臉部辨識技術越來越普及,其應用範圍涵蓋了社交媒體、手機解鎖等多個領域,並且在商業應用中展現了巨大的潛力、大放異彩。
接著讓我們來看看有哪些應用吧:
- 安全訪問控制:在公司或工廠,臉部辨識門禁系統逐漸普及。員工只需要刷臉就能辨別身份,相較門禁卡更為方便且更有安全保障。
- 支付安全:行動支付透過臉部辨識以確認使用者身分能使支付更加安全,更甚至是透過櫃台POS機刷臉直接線上支付,方便可靠。
- 海關身分驗證:透過臉部辨識,人們可以在海關更有效率地通過身分驗證,也可減少人工比對的誤差。
這些應用可不只是潮流,還帶來更安全、更方便、更智慧的商業體驗。當然,使用這些技術的同時,隱私和安全問題也是需要特別留意的,不能馬虎。
- 通過海關使用人臉辨識

- 人臉辨識手機解鎖

我們目前擷取人臉使用的開源套件為 yolov3。
Yolo 系列 (You only look once, Yolo) 是關於物件偵測 (object detection) 的類神經網路演算法,以小眾架構 darknet 實作,實作該架構的作者 Joseph Redmon 沒有用到任何著名深度學習框架,輕量、依賴少、演算法高效率,在工業應用領域很有價值,例如行人偵測、工業影像偵測等等。
Yolo 最大的特色是直接 end-to-end 做物件偵測,利用整張圖片作為神經網路的輸入,直接預測 bounding box 坐標位置、bounding box 含物體的 confidence 和物體所屬的類別。
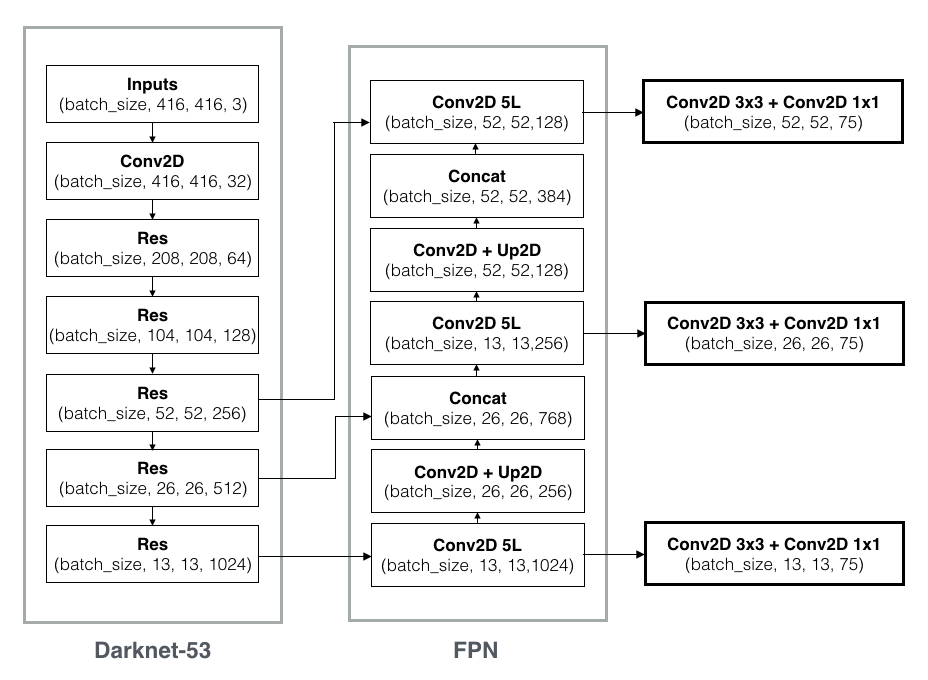
(1) Yolov3 的基底網路為 Darknet-53,有 53 層,隨著網絡層數不斷加深 (數量級從 20~30 層到 ~50 層),採用了一般類神經網路加深時常用的 ResNet 結構來解決梯度問題。
(2) 使用多層級預測架構以提升小物體預測能力,特徵層從單層 13x13 變成了多層 13x13、26x26 和 52x52,單層預測 5 種 bounding box 變成每層 3 種 bounding box (共 9 種),詳見網路結構圖。使用 FPN 的架構可以讓低層較佳的目標位置和高層較佳的語義特徵融合,並且在不同特徵層獨立進行預測,使得小物體檢測改善效果十分明顯。
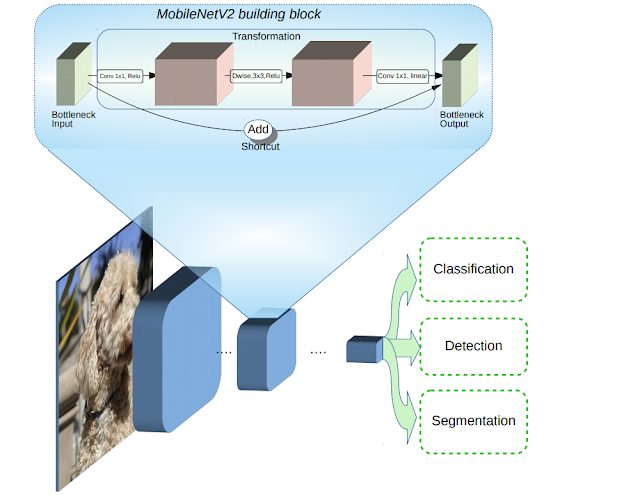
使用 MobilenetV2 實現人臉的辨識
MobileNetV2是以第一代為基礎來改善,延續了第一代透過深度可分離卷積(Depthwise Separable Convolution)的方式,來達到壓縮模型的目的,減少參數並提升運算速度,還新增了2項特性,層間的線性轉換方式(Linear bottleneck),以及Bottleneck之間的捷徑連接(Shortcut connections)。
MobileNetV2在深度可分離卷積方法前,增加了1X1的擴張層,來增加Channel數量,進而製造更多特徵,最後輸出時則不用線性整流單元(Rectified Linear Unit,ReLU)函數,為了避免特徵被破壞,改採用線性轉換的方式。 另一個特性則是,MobileNetV2與傳統的ResNet不同,ResNet是先壓縮維度,透過卷積萃取特徵,最後再擴張,而MobileNetV2則是相反的結構(Inverted residuals),先擴張,萃取特徵,最後再壓縮,因此,捷徑連接的是維度縮減後的結果。
MobileNetV2在深度可分離卷積方法前,增加了1X1的擴張層,來增加Channel數量,進而製造更多特徵,最後輸出時則不用線性整流單元(Rectified Linear Unit,ReLU)函數,為了避免特徵被破壞,改採用線性轉換的方式。 另一個特性則是,MobileNetV2與傳統的ResNet不同,ResNet是先壓縮維度,透過卷積萃取特徵,最後再擴張,而MobileNetV2則是相反的結構(Inverted residuals),先擴張,萃取特徵,最後再壓縮,因此,捷徑連接的是維度縮減後的結果。
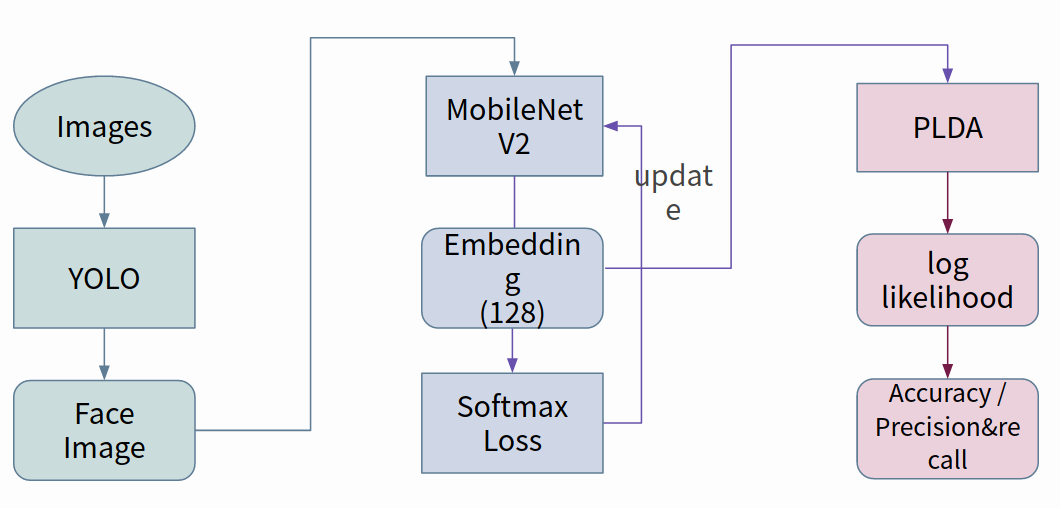
實作步驟:
(1)首先由 Yolo 將影像中的人臉擷取出來,並儲存其照片
(2)再使用 MoblieNetv2 對這張照片作特徵的提取,將其格式轉換成 embedding
(3)最後將得到的 embedding 由 PLDA 對其作分類,判斷是哪位已註冊的成員或是未註冊者
參考資料:
Yolov3 論文:YOLOv3: An Incremental Improvement
Yolov3 源碼:https://github.com/AlexeyAB/darknet
ModlieNet 論文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
PLDA 論文Probabilistic Linear Discriminant Analysis
1.收集資料:
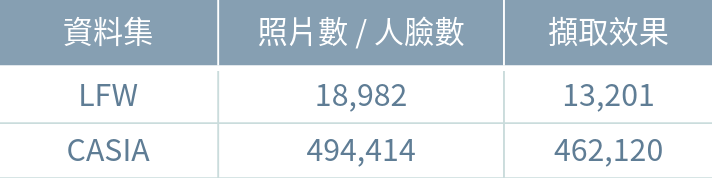
(1) 原始資料集 - WIDER FACE dataset
images : 12,880
faces : 159,420
(2) 以 dlib 擷取 - WIDER FACE dataset
training images : 18,880
faces : 10,921
2.YOLO V3 tiny - 訓練參數
width : 256
height : 256
batch size : 64
steps : 220,000
3.YOLO V3 tiny - results
FPS : 50
擷取結果 :
3.MobileNet V2 - 訓練參數
(1) 訓練集 - CASIA WebFACE
以 YOLO 擷取人臉
160*160*3
圖片 : 462,120張
(2) 參數設定
epoch : 150
batch size : 32
optimizer : Adam
learning rate :
( epoch : 0, learning rate : 0.001 )
( epoch : 100, learning rate : 0.0001 )
4.訓練結果
LFW 正確率:0.87
試玩程式說明:
將照片上傳到我們的 Server 進行臉部資料分析與建檔,接著您可以透過 Webcam 拍攝其他人或您自己的照片來跟建檔的臉部資料進行比對,我們的程式可以分辨是否為同一人。
流程:
- 按下START開始,等待鏡頭開啟。(若要切換鏡頭請點選SELECT DEVICE)
- 按Take picture拍一張正臉照片,在下方欄位輸入你的暱稱。不滿意可以按Cancel移除
- 點選Submit送出。在送出之後系統就可以辨識得到你了。

人臉反詐欺
為了防範這類問題,學界和業界都在積極研究「人臉反欺詐」(face anti-spoofing)技術,希望幫助人臉識別系統區分出真實的人臉和那些偽造或仿造的攻擊手段。使用時透過輸入圖片或是使用鏡頭攝影,人臉反欺詐的程式會判斷輸入的人臉是否屬於「活體」,也就是直接拍攝出沒有經過處理的人臉,例如沒有濾鏡、沒有經處理過而拍出的人臉。
在Deepfake技術盛行、媒體資訊以假亂真的年代,許多不法人士利用科技的便利散播不實資訊,甚至是藉此冒用他人身分來行騙的案例層出不窮,這時,人臉反詐欺技術在商業應用中扮演了守門員的角色,透過該技術能夠確保真實身份的驗證並提高民眾識別媒體資訊真偽的能力,有效防範詐欺行為。
讓我們來看看這項技術在現實生活中有那些應用吧:
- 身分驗證: 銀行、保險業務及支付機構可以通過人臉反詐欺技術確認用戶的身份真偽,防範非法交易和身份冒用。
- 考試作弊防範: 線上教育平台可以使用人臉反詐欺技術來防範考試作弊,確保考試過程的公平性和正確性。
- 媒體識別:人臉反詐騙軟體可以讓民眾在眾多資訊中辨別該資訊的真偽,減少被錯誤訊息誤導的機會。
以下是一些市面上現有的商品應用:
- Microsoft Video Authenticator

- Intel FakeCatcher

以往的作法都是輸入圖片,設計特徵提取鏡像反射、圖像失真、顏色等統計量特徵,合併後直接送入SVM或傳統分類器進行二分類。傳統的方式難以區別高清影像或高品質影像且泛化不佳。
傳統⽅法採⽤⼿⼯製作的特徵,如 LBP、HOG 和 SIFT 來提取紋理資訊並使⽤淺分類器,對決策邊界進行建模。這種⽅法使⽤的特徵沒有⾜夠的判別力,並且分類器的性能是有限的。這些⽅法往往會在預定義的資料集上overfitting,並且不能很好地泛化。

Learning Generalized Spoof Cues由⼀個 spoof cue generator和⼀個 aux classifier 組成,在 spoof cue generator 採⽤ U-Net 架構,在多個尺度上建⽴從編碼器到解碼器的連接以⽣成 spoof cue。選擇在 ImageNet 上預訓練的 ResNet18 作為編碼器 E,其中包含四個編碼器 Residual block。在編碼器 E 之後,由五個解碼器 Residual block組成的解碼器 D 將資訊解碼回以⽣成 spoof cue。在每個解碼器 Residual block 中,前⼀層的特徵圖透過最近鄰插值進行上採樣,然後我們加入⼀個 2×2 卷積。最後第四個解碼 Block 輸出使用 activation Tanh 使其正規化 -1到1。Decoder的五個block輸出進行三元组度量學習,輸出 spoof cue map 進行L1回歸正則化,最后將 spoof cue map 加回到原始圖像進行二分類。
參考資料:
1. Learning Generalized Spoof Cues for Face Anti-spoofing
-
收集資料:
(1)原始資料集 - FaceForensics++ Dataset (人臉視頻)
Actors - 基於 DeepFakeDetection 的正常原始人臉。
Youtube - 正常的人臉。
DeepFakeDetection - 加入 mask。
Deepfakes - 加入 mask,三種壓縮程度及泊松圖像編輯過的影像/圖像,基本上就是加上一些雜訊紋路,像截圖或是影印的樣子。
Face2Face - 加入 mask,臉部表情轉移到另一人。
FaceSwap - 加入 mask,換臉。
NeuralTextures - 加入 mask,材質紋路還有陰影的變化。
(2) 以 MTCNN 擷取視頻中人臉 - FaceForensics++ Dataset
-
LGSC模型訓練參數
-
loss_coef
- clf_loss:5.0
- reg_loss:5.0
- trip_loss:1.0
- lr:0.00008
- epoch:73
- optimizer:SGD
- batch size:16
- use_balance_sampler:True
- use_focal_loss:False
-
loss_coef
-
訓練結果
(1) FaceForensics++ Dataset
APCER(%):3.1
BPCER(%):2.25
ACER(%):2.675
Loss:2.12
Accuracy:0.99873
(2) 以 Oulu-NPU dataset 驗證泛化結果
Oulu-NPU 資料集中的真實和攻擊影片,是用六台移動裝置 (Samsung S6 edge, HTC Desire EYE, MEIZU X5, ASUS Zenfone Selfie, Sony XPERIA C5 Ultra Dual 和 OPPO N3) 的鏡頭錄製。共有三種不同的光照條件和背景場景 (Session 1, Session 2, Session 3),在本資料集中考量的攻擊方式為print 與 video-replay,這些攻擊是由兩台印表機 (Print 1, Print2) 和兩台螢幕 (Display1, Display 2) 創建。其中分成四個 protocol 做泛化性評估。
Protocol 1(光照及背景):
APCER(%):1.5
BPCER(%):1.86
ACER(%):1.68
Protocol 2(不同影印機及螢幕):
APCER(%):1.84
BPCER(%):1.91
ACER(%):1.875
Protocol 3(不同攝像頭):
APCER(%):2.732
BPCER(%):3.81
ACER(%):3.271
Protocol 4(綜上三個protocol):
APCER(%):7.97
BPCER(%):3.42
ACER(%):5.695
這是一個使用 LGSC 模型來檢測臉部活體與非活體的範例。 real - 真實世界的臉部圖像, fake - 包括 AI 產生的人臉、影印人臉照片(Print)、透過其他螢幕展示的二手人臉照片(Replay)。本 Demo 系統有以下三種展示方式,分別是採用我們的範例、上傳自己的圖檔、擷取視訊鏡頭。
流程:
- 點選 example / 上傳圖片 / 擷取臉部照片
- 您可以可參考各類型 fake 人臉圖像進行上傳測試,e.g. AI 產生的人臉、影印人臉照片(Print)、透過其他螢幕展示的二手人臉照片(Replay)。
- 等待模型辨識
- 得到最終預測結果(real / fake)

智能 AI 畫家


 Source:https://openai.com/blog/dall-e/
甚至可以產生物體的剖面圖:
Source:https://openai.com/blog/dall-e/
甚至可以產生物體的剖面圖:
 Source:https://openai.com/blog/dall-e/
Source:https://openai.com/blog/dall-e/
AI畫家在商業應用的用途十分廣泛,從海報中的插圖、美術藝術品,到時下流行的AI寫真,生活中AI智能畫家的應用案例不勝枚舉。
以下是一些智能AI畫家在商業上的應用場景:
- 品牌設計: AI畫家可以自動生成品牌標誌、圖形和其他視覺元素,幫助企業構建獨特的品牌形象。
- 廣告設計: 公司可以利用AI畫家生成引人入勝的廣告素材,提高廣告的視覺吸引力,吸引目標受眾的注意。
- 客制化產品設計: 利用AI畫家,公司可以為產品創建獨特的設計,包括包裝設計和產品外觀,滿足消費者對個性化的需求。
這些商業應用不僅可以提高創作效率,還能創造出更具創意和獨特性的內容,提供豐富的視覺體驗。當然,在使用AI畫家時需要注意版權和法律問題,確保合規使用。
一些市面上使用該技術所提供的服務:
- LINE-AI人臉寫真

- YouCam 線上圖片編輯-AI圖像自動生成

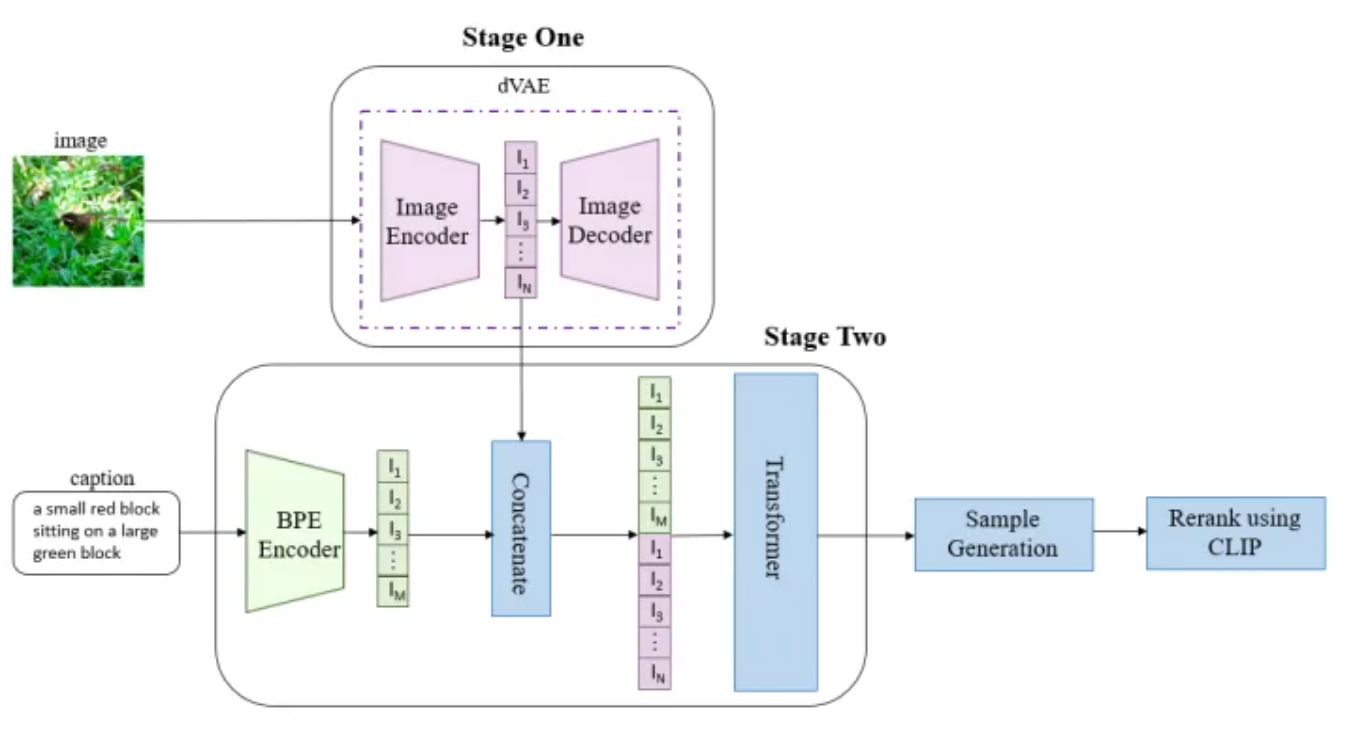
圖1:DALL-E 架構(來源:https://www.zhihu.com/question/447757686)
訓練主要分成三個階段, 前兩個階段對應到論文中提到的 Stage One 和 Stage Two。
- 第一階段: 訓練一個dVAE模型, 將每張 256x256 的圖片 encode 成 32x32(1024) 個token 表示。
- 第二階段: 用 BPE-encoder 對 text 進行編碼, 上限為 256 個token, 如果編碼後 token 不滿 256, 就會用 padding 去補滿。接著就有如圖1中間的部分, 將Stage1 圖片的 token(1024) 和 text 的 token (256) 合併, 得到總長 1280 的 token。最後將 token 輸入到 Transformer, 去生成圖片。
- 第三階段: 對生成的圖像做採樣, 並使用 CLIP 對採樣結果做排序, 得到與文本最符合的圖像。
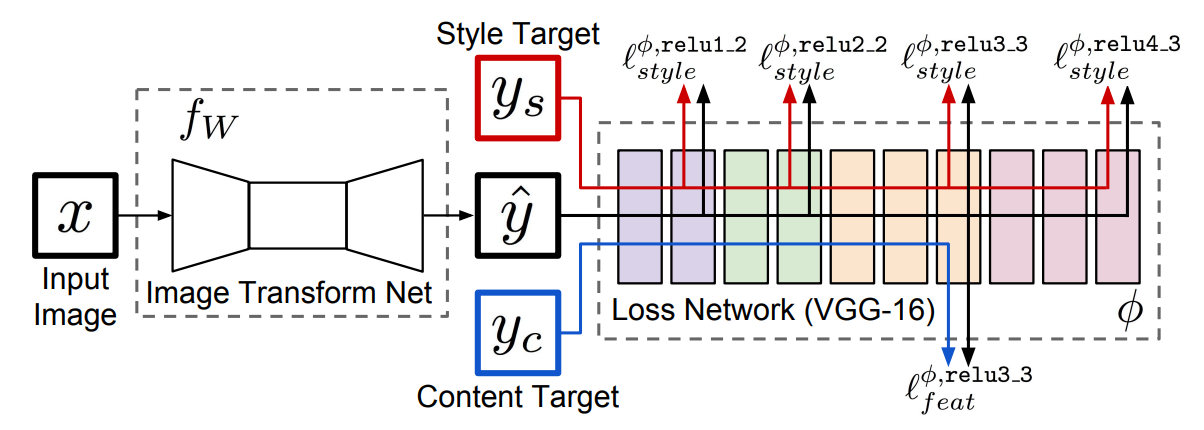
圖2: Style Transfer 架構 (來源: https://arxiv.org/pdf/1603.08155.pdf)
分為兩個 component:
- Image Transform Net : 將 input 轉換成想要的 output image (yhat)。
- Loss Network : 對輸出的 image (yhat) 計算 loss 。除了對照與 target 內容的特徵是否相似外, 也看是否和預期的 style (如: 顏色,文理等) 相似。
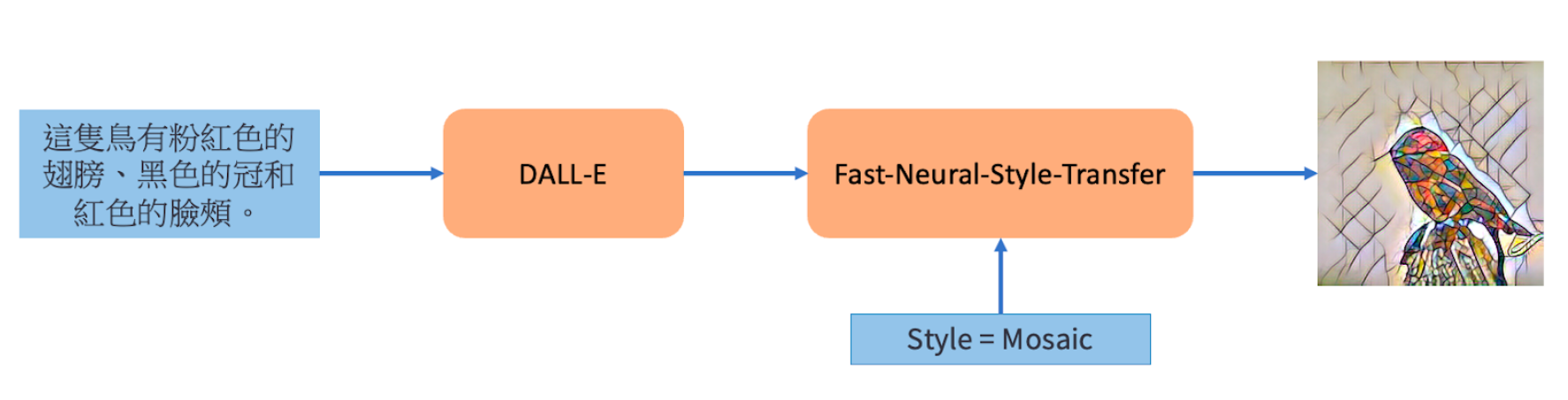
將文字透過 DALL-E 轉換成圖片後, 再輸入到 Fast-Neural-Style, 對圖片加上想要的style。
參考資料:
- DALL-E 論文 : https://arxiv.org/pdf/2102.12092.pdf
- Fast-Neural-Style-Transfer 論文 : https://arxiv.org/pdf/1603.08155.pdf
- Pretrain 模型(DALL-E) : https://github.com/lucidrains/DALLE-pytorch/discussions/131
- Pretrain 模型(Fast-Neural-Style-Transfer): https://github.com/eriklindernoren/Fast-Neural-Style-Transfer
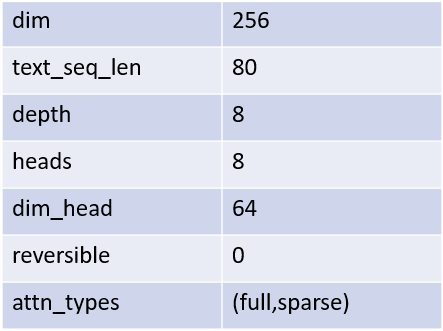
- Optimizer: Adam
- Learning rate: 從0.00045 * 8(gpu) 開始, 並使用 ReduceLROnPlateau
- Apply loss weighting (PR: Add loss weighting by following DALLE paper #134)
- No gradient clipping for better loss convergence
- However, for the larger dataset, gradient clipping is necessary to avoid NaN.
- Batch size: 110 * 8 (gpus)
-
CUB200
Text:這隻鳥有粉藍色的翅膀、紅色的腹部。
Style:Starry Night

-
COCO
Text:兩個男人坐在一張桌子的附近。
Style: Mosaic

- 智能 AI 畫家 -
本系統將展示透過 Dall.e 模型針對輸入的文字產生相對應的圖片,並將產生的圖片套上 Style Transfer 的效果(本系統提供三種效果 Starry Night、Cuphead及 Mosaic),最後呈現結果給使用者觀看;此外,若使用者想根據自己的句子產生圖片,亦可填寫連結內的表單,即可使用本系統產生對應圖片並進行下載,歡迎大家踴躍嘗試!
圖像修復
我們使用 Stable Diffusion 來做圖像修復,Stable Diffusion是一種圖像生成式模型,透過學習大量圖像數據,來理解圖像的結構和內容。使用時將圖片需修復地方塗白,讓模型預測缺失部分的內容,並生成與原圖協調一致的圖像,從而達到修復的效果。
在大量運用圖片的資訊年代,我們常常會遇到圖片效果不如預期的狀況出現,例如某些人物恰巧閉上眼睛、商品照的呈現方式不如預期……等等,這些意外瑕疵可能會降低照片的品質,但幸運的是,現今的圖像修復技術已經能夠輕鬆地解決這些問題。這些技術已經被廣泛應用於調整照片中的人物、事物以及它們的狀態,從而提升照片的品質和吸引力,讓使用者可以更容易地得到自己所期望的圖像。
目前常見的商業應用案例如下:
- 影像中物品狀態調整:調整影像中的物品狀態及方向,使商品圖片或攝影作品能夠更符合拍攝者期待。
- 人像狀態調整:讓照片中的人物可以改變表情、素顏上妝,使照片能夠達到使用者的要求。
接著來讓我們看看市面上有哪些相關的商品吧:
- Drag Your GAN

- 玩美彩妝

 Autoencoder (紅色框框)
Autoencoder (紅色框框)
- 此模型的作用是為了將圖片轉換成維度更低的潛在表徵, 可以想成把圖片重要的資訊壓縮成更低緯度的資料, 再把它傳到下個步驟。
- 在inference的部分, 會從去噪後的潛在表徵, 透過解碼去生成一張圖片。
- 輸入是已經加入噪音的圖片, 並學習如何將圖片去噪, 還原成原本沒有噪音的圖片。
- 將文字編碼後傳入 U-Net, 去控制圖片生成的分佈。這裡的作用,是要讓圖像生成時能依文字的語意去生成。
- Stable Diffusion 論文 : High-Resolution Image Synthesis with Latent Diffusion Models
- Pretrained 模型 : Stable Diffusion Image Inpainting
- 先上傳想要的圖片(圖片格式: JPG, PNG JPEG)
- 輸入您要的文字條件
-
設定參數 guidance scale 以及 Inference steps
- Guidance scale(引導尺度) : 控制模型遵循prompt的程度, 尺度越低, 模型的創造力越強, 尺度的越高, 創造力越低。
- Inference steps(推論步驟) : 模型降噪的步數, 步數越高, 會花越多時間(50steps/4secs) , 高的值可能會有好的效果, 但超過某個值後, 有可能會開始多出新的資訊。在30-50 的範圍通常會有不錯的效果。
-
選擇遮罩方式, 並生成圖片
- 刷子: 可以自由塗上想要遮罩的部分, 然後點選畫布左下角的下載按鈕, 再點擊 “Generate Image”。
- 自行準備: 自己上傳準備遮罩圖片, 再點擊 “Generate Image”。

語音合成與辨識
隨著科技發展,人機互動的情況已經越來越普及,像是Google小姐、智能導航、有聲書讀物等等,接已還繞在我們生活,而這些應用當中,語音合技術就扮演了相當重要的角色。
雖然語音合成的產品眾多,且能產生中文語音的技術也已成熟,但合成的中文語音大多數為『大陸腔調中文語音』,此結果的原因主要是因為可大量取得的中文訓練語料,皆由大陸腔調的語者錄製而成。因此我們希望透過不同的訓練資料、不同的訓練方式,用現有的中文訓練語料,合成好的語音品質、接近人類自然語音的『台灣腔調中文語音』。
一個完整的語音合成系統(Text-to-Speech),是由合成器與聲碼器所組成,合成器是將 我們輸入的文字輸出一個梅爾頻譜圖,聲碼器則將梅爾頻譜圖作為輸入,最後輸出一 個語音訊號,而目前我們所使用的合成器模型為Google提出的Tacotron-2,聲碼器模 型為ESPnet團隊開發的Parallel WaveGAN,兩者皆為可訓練的神經網路。
在合成器Tacotron-2,先使用訓練資料Biaobei(單一女性語者,12小時,大陸腔中文,3-5秒)加上將Biaobei的資料分割出短句(單一女性語者,37分鐘,大陸腔中文,0-1秒)加入資料集中當成預訓練,接著使用部份經過人工處理的NER(單一女性語者,2.2小時,台灣腔中文,5-8秒)加上將NER資料分割出短句(單一女性語者,12分鐘,台灣中文腔,0-1秒)繼續訓練。
• -語音辨識
現今語音辨識已經成為我們生活中常見的應用,並且可以帶來許多便利,例如 Siri、Google Assistant,我們可以透過講話使人工智慧 (AI) 來為我們做事。目前我們使用的開源套件為 ESPnet,它是一個專門處理語音任務的工具,主要是用 pytorch撰寫,並結合 kaldi進行前處 理。使用深度學習的方法替代了傳統自動語音辨識的訓練方式,用單個模型替換傳統自動語音 辨識的多個模塊,移除了對語音處理的方法使用,包含對音檔文本的強制對齊 。
傳統語音識別可由三個部分組成,聲學模型、詞典、語言模型,聲學模型通常代表的是我們說話的聲音,而一個詞可以分為多個音節組成,還需要詞典提供文字對應的音節,因此我們訓練聲學模型和詞典可以知道文字該對應哪些音節,擁有聲學模型後,語言模型包含了各個詞彙之間順序的機率大小,可以幫助我們知道怎樣排序詞彙可以更加通順,而其中的聲學模型和語言模型是分別訓練的,各自有各自的目標函數,由於各個模塊間不能互相取長補短,往往也使得最後所訓練出的網絡不能達到最優化。
語音合成架構由合成器與聲碼器組成,合成器使用的是Tacotron-2模型,聲碼器使用 的是Parallel WaveGAN模型。以下將各別簡單介紹。
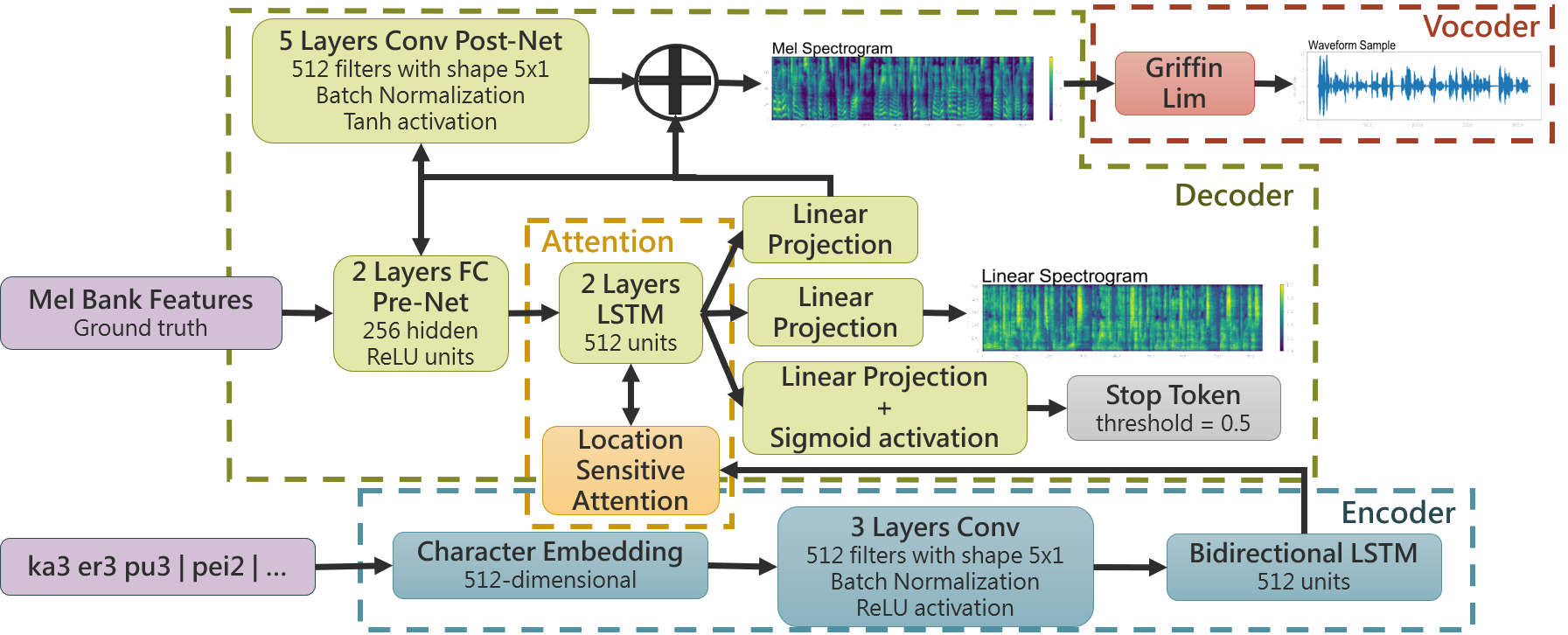
Tacotron-2由Google Brain於2018年提出,模型主要由 Encoder、Location Sensitive Attention、Decoder構成。資料進行訓練前必須做前處理,中文文本會經過轉換得到 漢語拼音,聲音訊號也會截取出梅爾頻譜圖。在訓練過程,文本作為Encoder的輸入 ,梅爾頻譜圖作為Decoder的輸入。整個神經網路由多層Convolution、LSTM、Fully Connected組成,透過對文字編碼、將與之成對的梅爾頻譜圖解碼,一次解碼出一個 frame,直至Stop token機制觸發,梅爾頻譜圖則產生完畢,如下圖一。
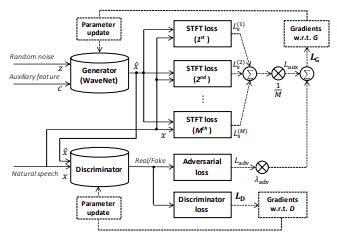
產生的梅爾頻譜圖透過聲碼器產生聲音訊號,這邊使用可訓練的神經網路Parallel WaveGAN代替演算法Griffin-Lim,藉此提升合成的語音品質。Parallel WaveGAN是 一個生成對抗網路,由一個Generator(這邊使用Waveglow)及一個Discriminator兩個 網路來生成語音。輸入為聲音訊號擷取出的梅爾頻譜圖以及高斯分佈所產生的random noise經由Generator生成出語音檔。而生成出的語音檔會與ground truth語音檔作為 Discriminator的輸入,並透過最小化Adversarial loss以及計算STFT loss來訓練 Generator網路生成出語音檔的品質,以及最小化Discriminator loss來訓練 Discriminator判別語音檔為真或假的能力進而加強Generator所生成因檔的品質,如下 圖二。
圖一、Tacotron-2模型架構(自行繪製)
圖二、Parallel WaveGAN(參考原始論文圖)
參考資料: Tacotron-2論文: https://arxiv.org/pdf/1712.05884.pdf
Tacotron-2源碼: https://github.com/NVIDIA/tacotron2
Parallel WaveGAN論文: https://arxiv.org/pdf/1910.11480.pdf
Parallel WaveGAN源碼: https://github.com/kan-bayashi/ParallelWaveGAN
• 語音辨識
目前使用的模型為混合 CTC-Conformer 的 End-to-End 架構。 在連續性時序分類( Temporal Classification, CTC )的訓練前,不需要將每個音框強制對齊到 label,因此 CTC 適用於輸入特徵與輸出標籤之間關係不確定的時間序列問題。
Conformer 為合併Transformer架構以及CNN module的架構,此作法是因為Transformer中 擅長在全域(global)的交互作用下抓取資訊,而CNN對於鄰近的(local)區域下有較好的效果, 因此合併這兩個架構而得到Conformer。
混合CTC-Conformer架構中,CTC以及Transformer Decoder會共享Conformer Encoder,並 且會結合CTC以及Transformer Decoder的loss function進行參數更新。網路架構如下圖三
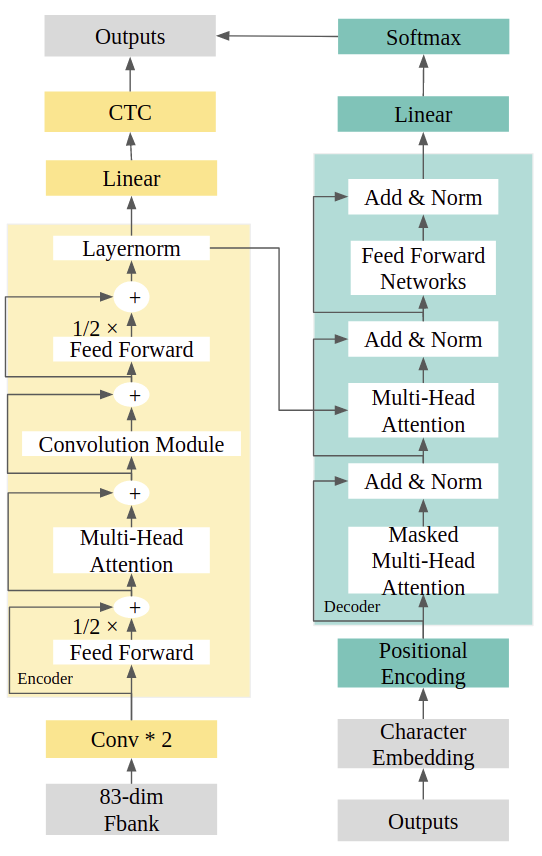
參考資料: Conformer : https://arxiv.org/pdf/2005.08100.pdf
Improving Transformer-based End-to-End Speech Recognition withConnectionist Temporal Classification and Language Model Integration: https://www.isca-speech.org/archive/Interspeech_2019/pdfs/1938.pdf
ESPnet: https://github.com/espnet/espnet
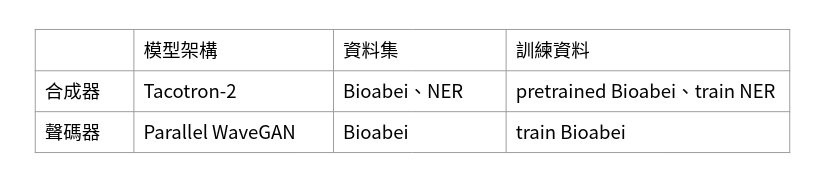
語音合成的架構由合成器Tacotron-2與聲碼器Parallel WaveGAN組成 以下將簡單介紹兩個模型的訓練資料及訓練方式,訓練資料參考表1。
在合成器Tacotron-2方面,使用Biaobei作為預訓練的訓練資料,為大陸腔中文,由單一女性語者錄製,而為了生成出品質較好的短音檔加入由資料集切割出的短語音檔加入資料一併訓練,總時長約12小時加上37分鐘,每筆音檔由5~7秒以及0~1秒組成,共11112筆音檔,接著使用NER的部份資料集繼續訓練,只使用部份資料的原因,第一原因是此為多語者資料集,容易導致訓練出來的合成品質較差,第二則是因為此資料集的每筆音檔皆為30秒,較長的音檔對於模型不易訓練,因此利用人工方式對音檔進行裁切,並對文本內容再次校正對齊,以致能產生的新資料量有限,這也是導致使用預訓練方式的原因。經過處理後並實際使用的資料為台灣腔中文,單一女性語者,總時長為2.5小時,每筆音檔約略8~10秒,前面提到為了生成出品質叫好的短音檔,將處理後的台灣腔中文資料在細切割出短音檔,共1870筆音檔。整體的訓練時間為2~3天。
在聲碼器Parallel WaveGAN的部份,是直接使用Biaobei資料集,為大陸腔中文,由 單一女性語者錄製,共10000筆音檔來做訓練。
表1、模型使用的資料集與訓練方式
• 語音合成
我們使用此架構自行訓練中文語音模型,使用 NER、Aishell 及科技大擂台做為訓練資料,約 221 小時,共85,106筆音檔(如表2)。
目前有兩個測試集文本,其中一個測試集為FSRC2018這個比賽所提供的測試集。
另一個測試集為自行錄製的音檔,三位語者,約0.75小時,共1008筆音檔。測試集文本內容 為中山無人書店聊天機器人中使用者常用的語句 (如表3)。
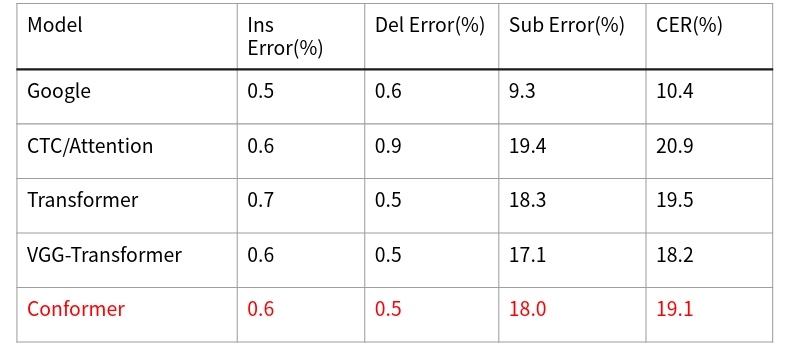
目前模型準確率在這兩個測試集下可以達到88.8%以及80.9% (如表4、5)。
準確率為( 1 - CER ) %,CER (Character Error Rate) 計算方式為 (辨認錯誤的中文字數量 (插入+刪除+替換) / 答案的總中文字數量 * 100%。
表2、
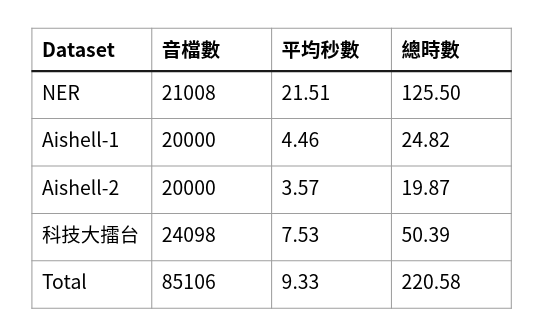
表3、
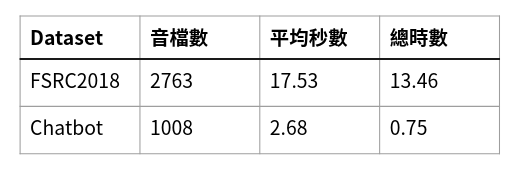
表4、
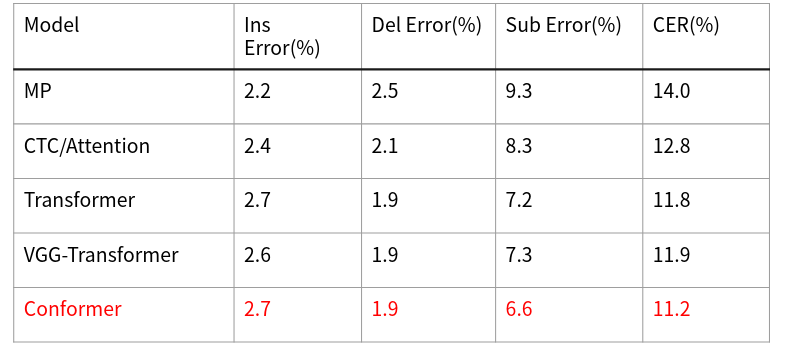
表5、
試玩程式說明:
此 Web 程式可開啟麥克風進行錄音,可將語音 (中文) 轉換成文字內容。
操作流程:
- 按下 Record 開始錄音 (若要暫停則按下 Pause,恢復錄音請按 Resume)
- 錄完音後按下 Stop 可結束錄音
- 出現剛才錄製的音檔
- 點選底下 Save to disk 可下載音檔
- 按下 Recognize 並稍待幾秒後將出現辨識後的文字

• 語音合成
試玩程式說明:
此網頁可進行語音合成。在『請輸入文字』處,輸入想要合成的文字,按下"合成"按鈕,即可將文字合成語音。播放音檔的右邊處,可下載此合成音檔。
有三種合成方式:
- 台灣腔語音:支援中文文字合成
- 北京腔語音:支援中文文字合成
- 多語言語音:支援中英混合文字合成

模型壓縮的工具探索
近年來深度學習受到了大量的關注,也在許多領域的應用上得到了令人驚呼的準確度。然而,深度學習模型龐大的參數數量限制了在算力有限的行動設備與邊緣設備上的應用。為克服這個挑戰,「模型壓縮」成為研究重點。這方向追求在壓縮模型大小、提升推論速度的同時,保持模型原本的高準確度。解決這一實務難題對未來深度學習應用至關重要。
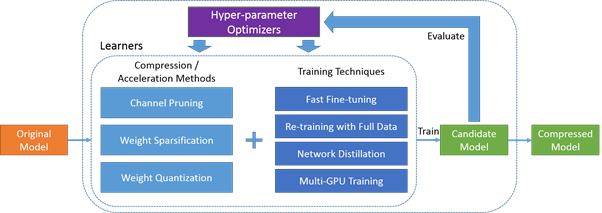
我們團隊所使用的模型壓縮工具分別是由Tencent騰訊開發的PocketFlow和Microsoft開發的NNI。PocketFlow運用「通道剪枝」,去除模型中不必要的部分;「權重稀疏化」,讓模型中的一些權重變得更輕;以及「參數量化」,將模型的參數表示方式做更有效率的轉換,透過此三種方法使模型更加輕盈。另外,NNI的獨特之處在於自動化,它能智能選擇最佳的壓縮方法,無需手動調整。NNI還提供直觀的可視化介面,方便使用者了解模型壓縮效果,即使對機器學習不太熟悉的人也能輕鬆應用。
期望透過上述介紹,為那些欲進行深度學習研究卻受限於硬體設備的使用者提供一條清晰的指導,能夠更輕鬆且充分地探索深度學習領域。
隨著機器學習、深度學習的研究領域崛起,各項應用AI科技的產品相繼問世,如時下流行的ChatGPT模型便是經過壓縮的大型語言模型;在大型模型盛行的現在,許多的研究者常常受硬體設備的運算能力不足限制,因此無法輕鬆地進行這方面的探索,這時,使用模型壓縮工具就能解決硬體設備限制上的問題,讓使用者能夠更自由地進行這些研究;此外,透過模型尺寸的壓縮,也能夠使這些模型在實際應用上更有效率的運行。
市面上的模型壓縮產品如本專案所使用的:
- Tecent騰訊所開發的PocketFlow
- Microsoft 所開發的 NNI
NNI甚至提供了介面讓不熟悉機器學習的使用者也能輕鬆使用。

本文主要介紹兩款主流的模型壓縮工具的使用經驗:
以及 4 個我們測試過的模型壓縮演算法,包括:
Tencent 騰訊 - PocketFlow
sourse: https://pocketflow.github.io/
PocketFlow 是一套由騰訊開發,基於 TensorFlow 的模型壓縮工具,主要框架是結合了模型壓縮演算法、模型蒸餾與參數微調。而模型壓縮演算法的部分包含了 3 個壓縮方法,分別是:Channel Pruning、Weight Sparsification 與 Parameter Quantization。
Microsoft - NNI ( Neural Network Intelligence )
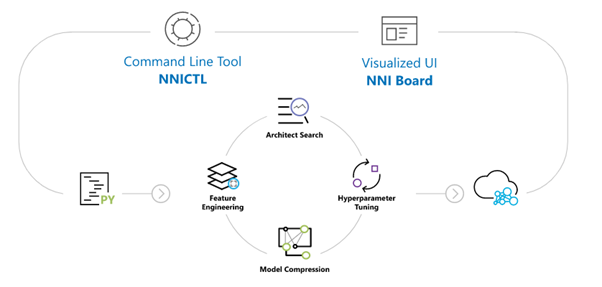
Microsoft 開發的 NNI 相對於 PocketFlow,是一套更加完整與易用的工具,除了模型壓縮演算法之外,NNI 也結合了模型架構搜尋、特徵工程等等在建立深度學習模型時可以使用的工具,建立了一套完整的從建模到模型壓縮的工具生態系。此外,NNI 也相容 Pytorch 框架,更在 Pytorch 框架上開發出能夠真正刪除模型壓縮後冗餘的參數,使模型的檔案大小與運算時間實際減少的套件。
演算法:
PocketFlow - Channel Pruning
Channel Pruning 的演算法是從各個卷積層之中選出比較重要的 Filter,這個壓縮器實現了 He et al. [3] 在 2017 年提出的方法,先用 LASSO 計算出各個 Channel 的重要性,在最小化壓縮前後的 feature map 的重建誤差的條件下依序選擇要保留的 filter。
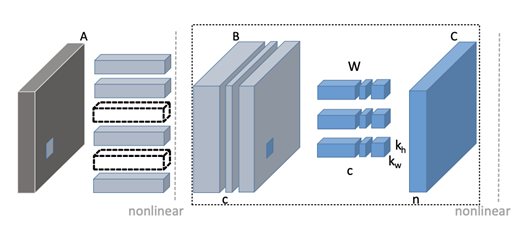
PocketFlow - Discrimination-aware Channel Pruning
Discrimination-aware Channel Pruning 使用了不同的方式來選擇重要的 Filter,這個壓縮器根據 Zhuang et al. [4] 在 2018 年提出的方法,提出DCP (Discrimination-aware channel pruning) 方法一方面在中間層添加額外的 discrimination-aware loss (用以強化中間層的判斷能力),另一方面也考慮特徵重建誤差的 loss,綜合兩方面 loss 對於參數的梯度資訊,決定哪些為需要被裁剪的 channel。
PocketFlow - Uniform Quantization
精度削減 ( Quantization ) 透過使用較少的位元來表示每個參數與權重的方法,來達到減少模型的記憶體佔用的目的。這種方法雖然無法減少模型的計算量 ( FLOPs 浮點運算次數 ),不過卻是一種相對直覺且壓縮過程非常簡單的方法。例如,TensorFlow 預設的浮點數精度為 32 位元,我們可以透過將權重的浮點數精度降低為 8 位元,使得模型的權重只需要原先的四分之一左右的儲存空間。
NNI - Lottery Ticket Hypothesis Algorithm
NNI 的這個壓縮器實現了 ICLR 2019 最佳論文「The Lottery Ticket Hypothesis: Finding The Sparse, Trainable Neural Network」[5] 的概念:一個大型類神經網路包含了大量的子網路,這些子網路當中有些在原本的模型中具有影響力,有些則否。因此只要找出這些對預測具有影響力的子網路,去除影響力低的子網路,那麼保留的子網路的集合也能夠具有與完整模型相同的能力。
這個壓縮方法使用了迭代的權重剪枝過程,意即重複的找出要保留的參數子集合之後,再從這個子集合繼續找出要保留的子集合的循環,直到剩餘的參數量滿足一開始設定的參數稀疏度。
References:[1] https://pocketflow.github.io/
[2] https://nni.readthedocs.io/en/latest/index.html
[3] https://arxiv.org/abs/1707.06168
[4]https://arxiv.org/abs/1810.11809
[5]https://arxiv.org/abs/1803.03635
PocketFlow 測試結果:
我們使用 PocketFlow 來壓縮以 CASIA webface dataset 訓練的 Mobilenet v2 模型,我們測試的壓縮方法有 Channel Pruning、Discrimination-aware Channel Pruning 以及 Uniform Quantization。
其中,測試的條件控制為:
Channel Pruning
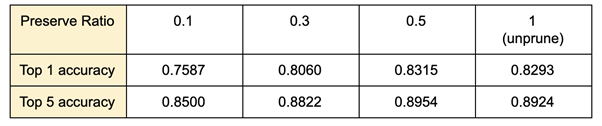
由上表可以看出在使用 Channel Pruning 的情況下,保留的參數量在 50% 以上時,可以維持與原始模型接近的準確度。
比較不同壓縮演算法
為了探討不同壓縮方法在相同壓縮比率下的表現,我們比較了 Channel Pruning、Discrimination-aware Channel Pruning 在保留 3 成的權重,Uniform Quantization 在 8 bit 的情況下的準確度與模型檔案大小。
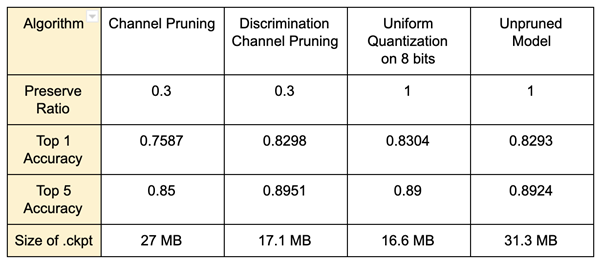
雖然模型的 .ckpt 檔大小在壓縮之後有變小,但是實際檢視模型參數量時,會發現壓縮後的模型的浮點運算次數減少的原因在於 PocketFlow 會產生一個 Mask File 紀錄需要被刪掉的參數,在載入模型時同時載入這些遮罩,來避免這些被遮罩的參數參與運算。
NNI 測試結果:
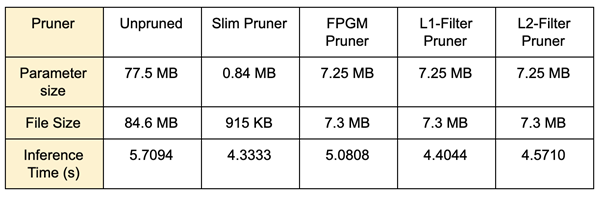
Lottery Ticket Hypothesis Pruner
由於 Lottery Ticket Hypothesis Pruner 使用了 Fine-grained 的壓縮方式,這種 parameter-wised 的壓縮方法會造成模型架構的不規則化,因此經過 Lottery Ticket Hypothesis Pruner 壓縮後的模型無法套用 NNI 的 speed up 功能,所以即使這種壓縮方式可以只保留 10% 參數的清況下仍然能維持與原始模型接近的準確度。
實驗設計:

Speed Up Function
由於 PocketFlow 目前只能做到「找出不重要的參數」並且加上遮罩,使這些參數不會在運算時被使用,卻不能真正的修改模型結構,將這些參數從模型中真正的移除。而 NNI 開發了一個基於 pytorch 框架,用於刪除這些被遮罩住的參數的工具,所以我們在 NNI 的測試項目主要在於刪除參數功能的部分。
實驗設計:
此程式提供LeNet,ResNet-20 與 ResNet-34兩種模型供您選擇,選擇模型之後,程式會先顯示原始模型在 MNIST 資料及上的準確度。之後您可以調整要保留的模型參數量與模型壓縮方法,選擇完成後,系統會使用 Microsoft 開發的 NNI 壓縮您選擇的模型,並且呈現壓縮之後模型的表現。

推薦系統
隨著電子商務規模的不斷擴大,商品個數和種類快速增長,顧客需要花費大量的時間才能找到自己想買的商品,這種瀏覽大量無關的訊息和產品過程會使消費者不斷流失。由此推薦系統應運而生,推薦系統是一種資訊過濾系統,透過用戶對於不同項目的評分紀錄,能夠預測用戶對於其他項目的評分或是偏好,進而向用戶推薦更可能感興趣的項目。
推薦系統的強大威力因此備受矚目,漸漸地出現在非電子商務的應用場合,隨後逐漸佔領各行各業,線上影音串流平台 Netflix 將過去用戶觀看的紀錄訓練出推薦模型,進一步推薦更適切用戶偏好類型的電影、影集;社群交友軟體 Tinder 藉由個人的擇友偏好來推薦你更適配的好友;論文搜尋平台 Google Scholar 甚至能夠推薦你更多相關的論文,讓學者更能夠掌握研究趨勢。
推薦系統分類主要為以下三者:- 基於內容的推薦系統 (Content-based Recommender System):
通過相關特徵來定義用戶或是項目,依據用戶資料與待預測項目的批配程度進行推薦,盡力向用戶推薦類似於過去喜歡的項目,例如:用戶喜歡看動作片,而推薦系統則會盡力去推薦用戶喜歡的動作片。基於內容的推薦系統的優點是簡單且有效;缺點是提取特徵的能力有限,就算過分細化特徵,依舊無法為用戶推薦不同種類的項目,只能推薦用戶已有興趣的項目。這種推薦系統被限制在容易分析內容的項目推薦。 - 協同過濾推薦系統 (Collaborative Filtering Recommender System):
相較於傳統的基於內容的方法透過直接分析內容來進行推薦,協同過濾推薦系統分析用戶的興趣,在用戶群中找到與指定用戶有相似興趣的用戶群,綜合興趣相投、擁有共同經驗的用戶對於所有項目的喜好程度預測來作喜好預測排序再推薦。近年研究發展出許多數學運算方法讓電腦在計算協同過濾推薦的效率提升,協同過濾推薦系統又分為以使用者為基礎(User-based)的協同過濾跟以項目為基礎(Item-based)的協同過濾,後續將會有詳細介紹。協同過濾推薦系統的優點是能夠過濾難以自動內容分析的資訊,像是音樂或是藝術品,由於是興趣相投方式的推薦,也往往能夠找出用戶意想不到的項目;缺點則是系統對於新用戶掌握度不高,難以推薦相關興趣的項目,推薦品質會較差,而當用戶以及項目過大,也會產生評分矩陣過於稀疏延伸矩陣分解的問題。 - 混合推薦系統 (Hybrid Recommender System):
綜合以上兩種主要的推薦系統方法,混合推薦系統組合以上兩種推薦系統方法以彌補彼此間的優缺點,混合推薦系統組合的方式又分為「循序組合」、「線性組合」,循序組合是在不同用戶使用階段,使用不同推薦方法,來產生該階段所需的協果,例如:先利用基於內容的方式找出相似的使用者,接著再利用協同過濾方式來作推薦;而線性組合是同時使用兩種以上的推薦系統方法,分別產生個別的推薦結過,在賦予各個方法個別不同權重,加權之後即可得到最後的推薦結果。
本篇範例以第二種方法「協同過濾推薦系統」為主的演算法,因為協同過濾推薦系統對於資料格式要求低,方便各位使用者實現應用。將會以 R 的套件 RecommenderLab 來運行基於用戶的協同過濾(User-based CF)和基於項目的協同過濾(Item-based CF),除此之外也會介紹透過 Python PyTorch 實作的 DeepRecommender 深度學習演算法來進行協同過濾推薦。
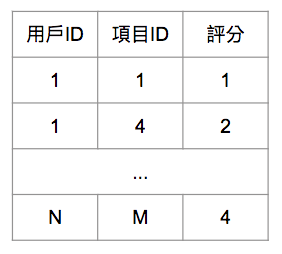
功能:將N個用戶對於M個項目評分的歷史資料整理成以下資料表形式,而用戶對於項目列表至少給予一筆以上的評分。透過歷史評分資料,推薦系統會將資料轉換成 N * M 的評分矩陣,再去學習用戶跟項目之間的連結關係。後續預測時,您可以輸入一名新用戶對於多筆不同項目的評分,系統將會推薦給適合的項目給這位新用戶。
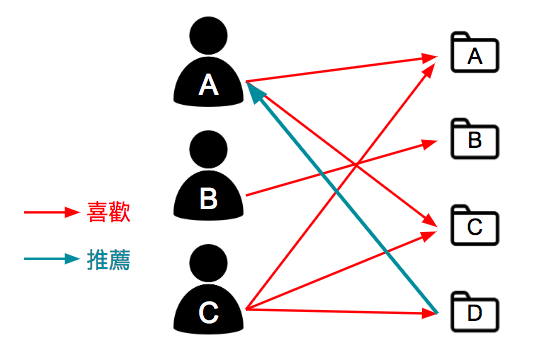
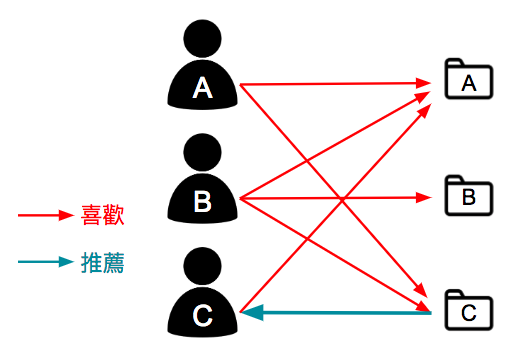
基於用戶協同過濾先尋找與目標用戶有相同喜好的鄰近用戶,然後根據目標用戶的鄰近用戶的喜好產生對目標用戶的推薦。基本原理就是利用用戶喜好行為的相似性來互相推薦用戶可能感興趣的項目,如下圖所示,用戶 A 喜歡項目 A 跟 C,用戶 B 喜歡項目 B ,用戶 C 喜歡項目 A、C 跟 D,從這些用戶的歷史偏好資訊中,我們可以發現用戶 A 跟用戶 C的偏好很類似,而用戶 C 還同時喜歡項目 D,那麼我們可以推斷用戶 A 也可能喜歡項目 D,因此將項目 D 推薦給用戶 A。
基於項目的協同過濾(Item-based CF)技術描述:
根據所有用戶對於項目的評價,發現項目彼此之間的相似度,然後根據目標用戶的歷史偏好資訊將類似的項目推薦給該用戶,如下圖所示,用戶 A 喜歡項目 B 跟 C,用戶 B 喜歡項目 A、B 跟 C,用戶 C 喜歡項目 A,從這些用戶的偏好資料中可以認為項目 A 跟項目 C 比較類似,喜歡項目 A 的都會喜歡項目 C,基於這個案段用戶 C 也可能喜歡項目 C,所以推薦項目 C 給用戶 C。
DeepRecommender 提出的 DeepAutoencoder 演算法技術描述:
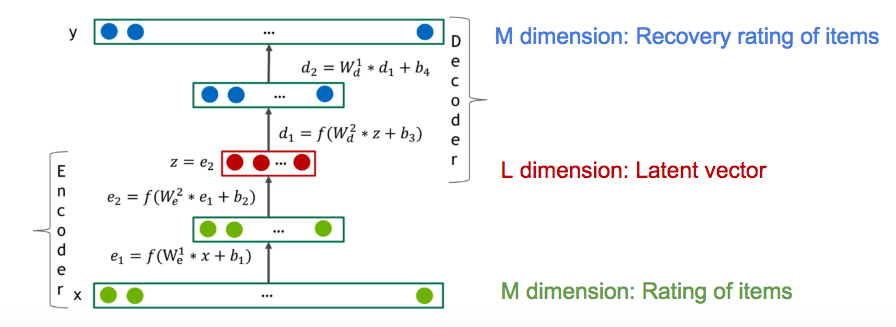
DeepRecommemder 為 NVIDIA 於 2017 年 8 月 5 日發表於 arXiv 。使用的程式語言為 Python 3.6,另外使用 PyTorch 作為深度學習模型框架。而 DeepRecommemder 是屬於協同過濾式推薦系統。 DeepAutoencoder 藉由多層的 Autoencoder 來訓練用戶跟項目間的評分關係。DeepAutoencoder 會將 M 個維度的資料壓縮成 L 個維度,再將其推回 M 個維度,試圖還原原本 M 個維度的原始資料,如下圖所示。由於 DeepAutoencoder 學習到用戶跟項目的關係,您可以輸入一名新用戶對於多筆不同項目的評分,接著 DeepAutoencoder 會試著還原所有的評分矩陣,換句話說,能夠自動填上它認為新用戶對於不同項目各自該有的評分,再以還原的評分進行推薦即可。
訓練參數為:DeepAutoencoder 之網路層數、神經元數量跟激勵函式及位於 z 層的 Dropout 率。
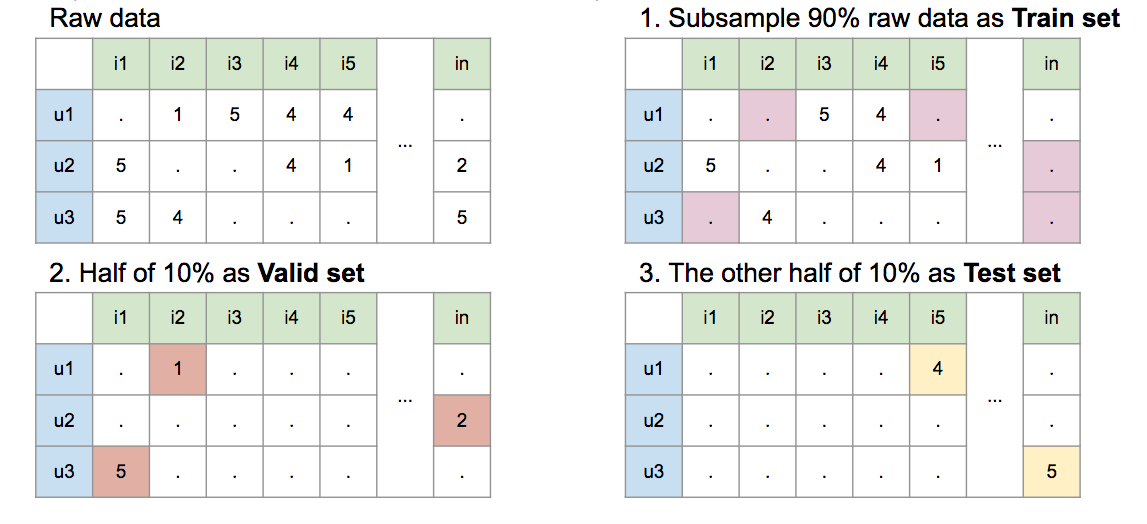
原始資料中會有用戶對不同項目的評分,DeepRecommender 會將這些評分切成 90% 部分為訓練資料用以訓練 DeepAutoencoder,5% 為驗證集,用以驗證訓練的 DeepAuencoder 之水準,剩餘 5% 為測試集,作為最後測試結果。
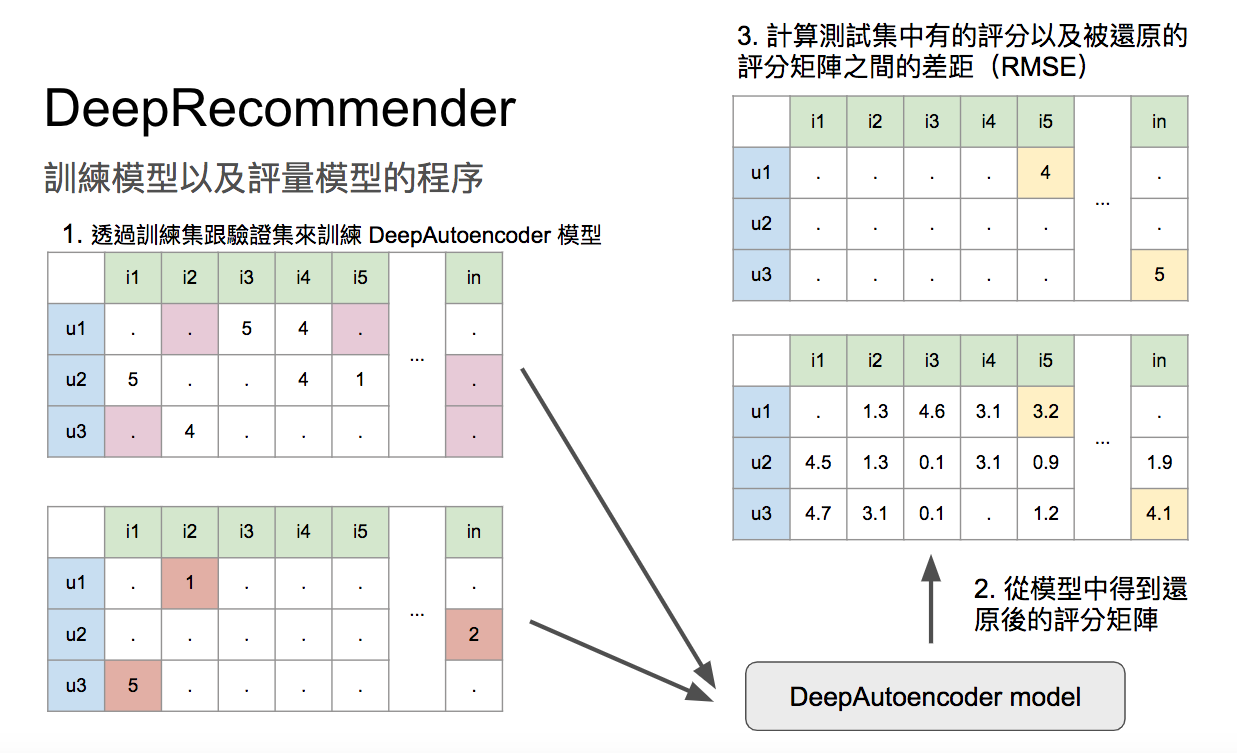
參考資料:
1. RecommenderLab 2. DeepRecommender
- Movielens:
包含 6,040 位用戶對 3,706 部電影,總共一百萬筆的評分紀錄,評分矩陣稀疏率約為 95.5326%。 - Netflix:
包含 67,878 位用戶對 10,677 部電影,總共一千萬筆的評分紀錄,評分矩陣稀疏率約為 98.6202% 評分紀錄從 1999-12-01 到 2005-11-31。
- RecommenderLab, User-based Collaborative Filtering.
- RecommenderLab, Item-based Collaborative Filtering.
- DeepRecommender, DeepAutoencoder.
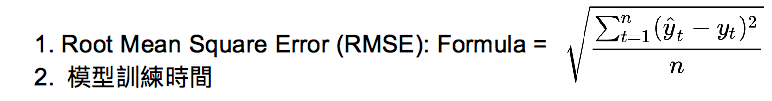
◎ 實驗一:
測試資料:Movielens,包含 6,040 位用戶對 3,706 部電影,總共一百萬筆的評分紀錄,評分矩陣稀疏率約為 95.5326%。
測試結果:
| DeepRecommender (1080ti * 1) | IBCF | UBCF | |
|---|---|---|---|
| RMSE | 0.950686 | 1.2904 | 0.9518 |
| Training Time | 46 sec | 12 min 7 sec | 0.2 sec |
◎ 實驗二:
測試資料:Netflix,包含 67,878 位用戶對 10,677 部電影,總共一千萬筆的評分紀錄,評分矩陣稀疏率約為 98.6202%。
測試結果:
| DeepRecommender (1080ti * 1) | IBCF | UBCF | |
|---|---|---|---|
| RMSE | 0.9121 | NA | 0.9612 |
| Training Time | 35 min 21 sec | NA | 2.15 sec |
試玩程式說明:
本推薦系統會列出十幾部電影讓您評分,評分完後上傳評分結果,系統會對您的評分進行分析,並列出幾部您可能會喜歡的電影。
按下「試玩推薦系統」按鈕,開始試玩:
